AutoRAG 是如何工作的
AutoRAG 为您设置和管理 RAG 流水线。它连接了索引、检索和生成所需的工具,并通过定期与您的数据同步来保持一切最新。一旦设置完成,AutoRAG 会在后台对您的内容进行索引,并实时响应查询。
AutoRAG 由两个核心过程组成:
- 索引: 一个异步后台过程,监控您的数据源以获取更改,并将您的数据转换为用于搜索的向量。
- 查询: 一个由用户查询触发的同步过程。它检索最相关的内容并生成上下文感知的响应。
索引是如何工作的
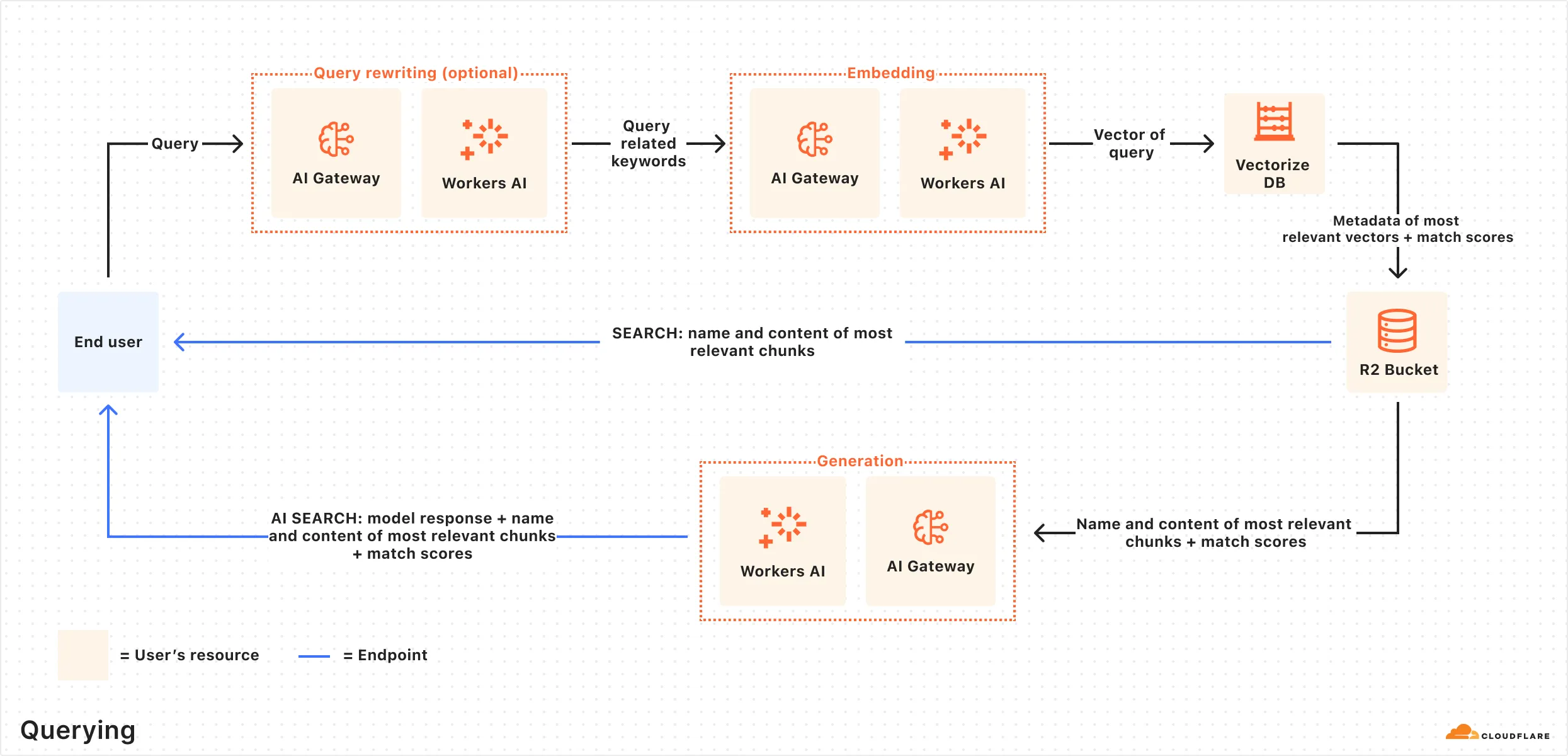
当您创建一个 AutoRAG 实例并连接数据源时,索引会自动开始。
在索引过程中会发生以下情况:
- 数据摄取: AutoRAG 从您连接的数据源中读取数据。
- Markdown 转换: AutoRAG 使用 Workers AI 的 Markdown 转换 将 支持的数据类型 转换为结构化的 Markdown。这确保了不同文件类型之间的一致性。对于图像,使用 Workers AI 进行对象检测,然后进行视觉到语言的转换,将图像转换为 Markdown 文本。
- 分块: 提取的文本被 分块 成更小的部分,以提高检索的粒度。
- 嵌入: 每个块使用 Workers AI 的嵌入模型进行嵌入,将内容转换为向量。
- 向量存储: 生成的向量以及文件名等元数据存储在您 Cloudflare 账户上创建的 Vectorize 数据库中。
在初始数据集被索引后,AutoRAG 将定期检查您的数据源中的更新(例如,添加、更新或删除),并索引更改,以确保您的向量数据库是最新的。
查询是如何工作的
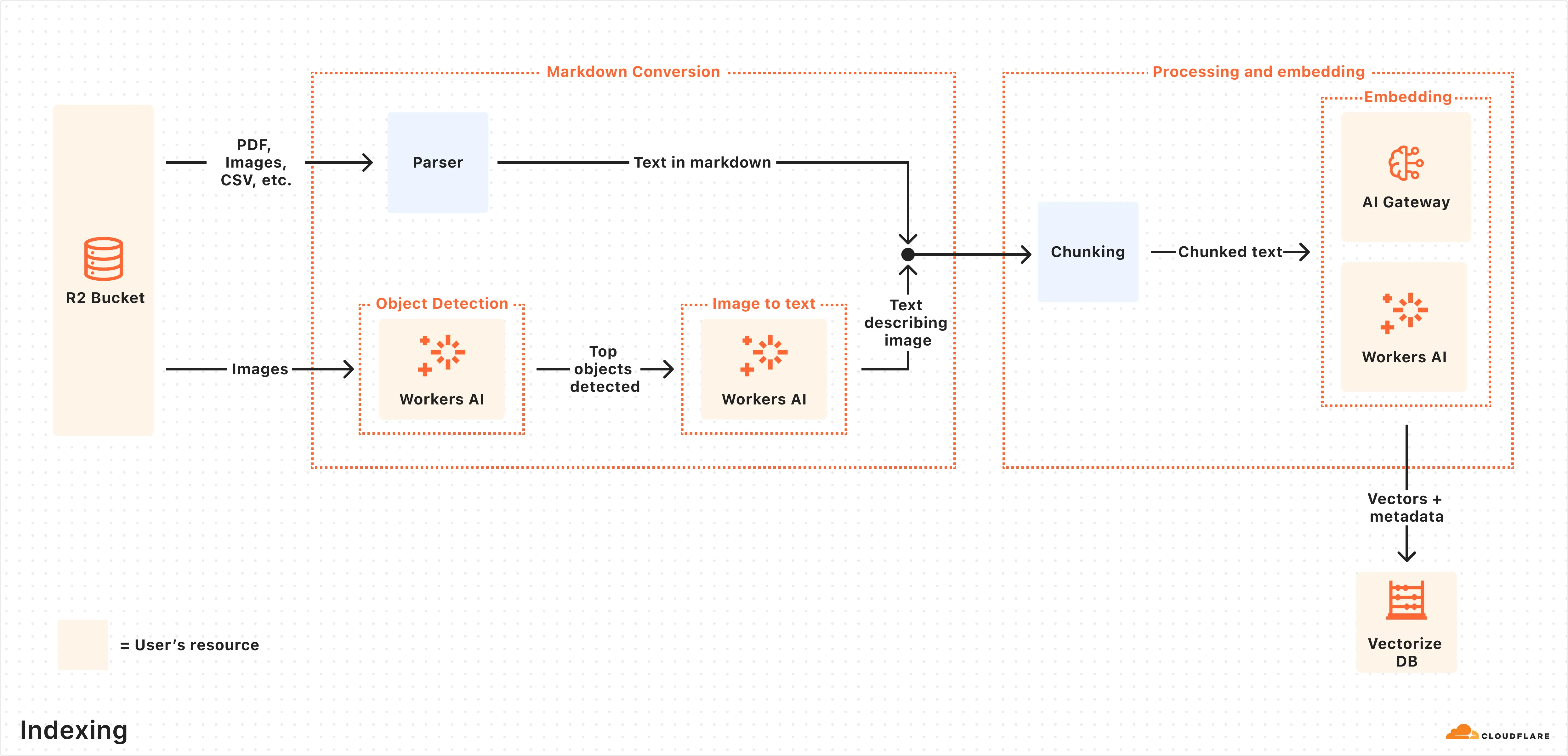
一旦索引完成,AutoRAG 就准备好实时响应最终用户的查询。
以下是查询管道的工作原理:
- 接收来自 AutoRAG API 的查询: 查询工作流程在您向 AutoRAG 的 AI 搜索 或 搜索 端点发送请求时开始。
- 查询重写(可选): AutoRAG 提供了使用 Workers AI 的 LLMs 重写输入查询 的选项,通过将原始查询转换为更有效的搜索查询来提高检索质量。
- 嵌入查询: 重写后的(或原始)查询通过与嵌入您的数据所使用的相同嵌入模型转换为向量,以便与您的向量化数据进行比较,以找到最相关的匹配项。
- 查询向量化索引: 查询向量在与您的 AutoRAG 关联的 Vectorize 数据库中 查询 存储的向量。
- 内容检索: Vectorize 返回最相关块的元数据,原始内容从 R2 存储桶中检索。如果您使用的是搜索端点,此时将返回内容。
- 响应生成: 如果您使用的是 AI 搜索端点,则使用 Workers AI 的文本生成模型,根据检索到的内容和原始用户查询生成响应,这两者通过 系统提示 结合。模型返回上下文感知的响应。